Users
Cardholders, Merchants, Payments & Operations Teams
Industry
Financial Services / Payments
Product Stage
Mature, High-Throughput Platform
Payment Routing & Reliability
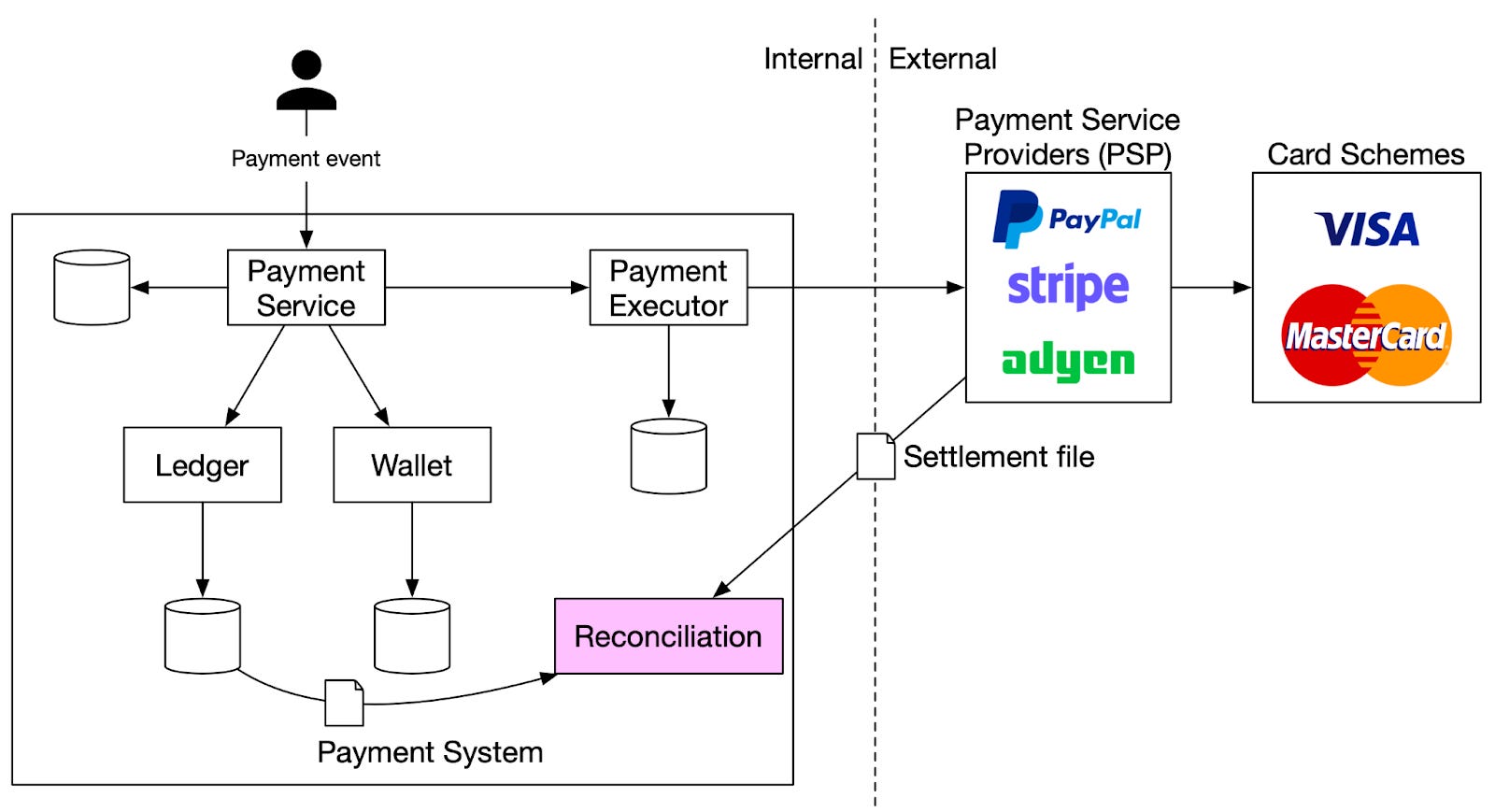
Payment routing sat quietly behind every successful transaction, determining where requests were sent, how failures were handled, and how quickly the system recovered when something went wrong. When routing worked well, transactions flowed without interruption. When it didn’t, the impact was immediate resulting in increased declines, merchant issues, and operational escalations.
Unlike visible product features, routing and reliability decisions were exercised most under stress: traffic spikes, partial outages, upstream failures, or degraded network conditions. The challenge was designing a system that behaved predictably not just in normal conditions, but when dependencies failed in messy, real-world ways.
Context and Scale
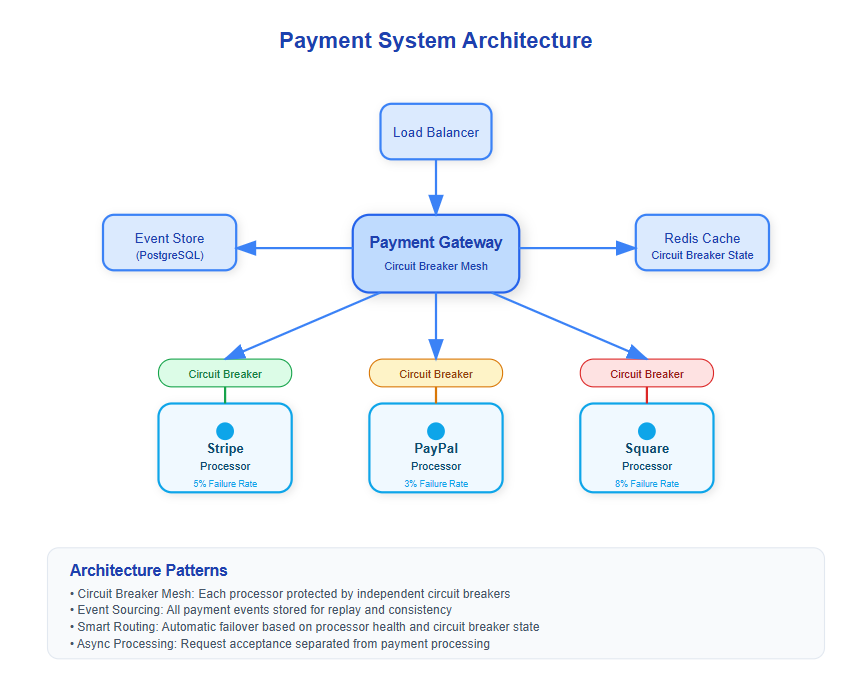
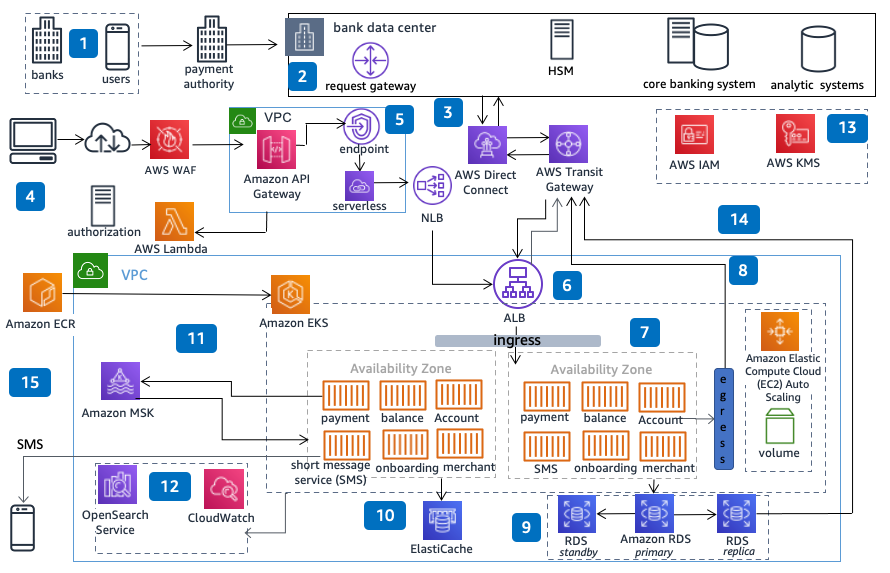
The routing layer operated at the heart of a high-throughput payments platform, handling traffic across multiple processors, networks, and downstream systems.
At peak volume, even small inefficiencies or misrouted traffic could cascade quickly. Latency budgets were tight, retries had to be controlled, and failover behavior needed to be fast enough to protect customer experience without amplifying load elsewhere in the system.
Reliability here wasn’t about avoiding failure altogether, it was about failing safely and recovering quickly.
The Problem
As transaction volume and system complexity increased, routing logic that had worked under simpler conditions became harder to reason about.
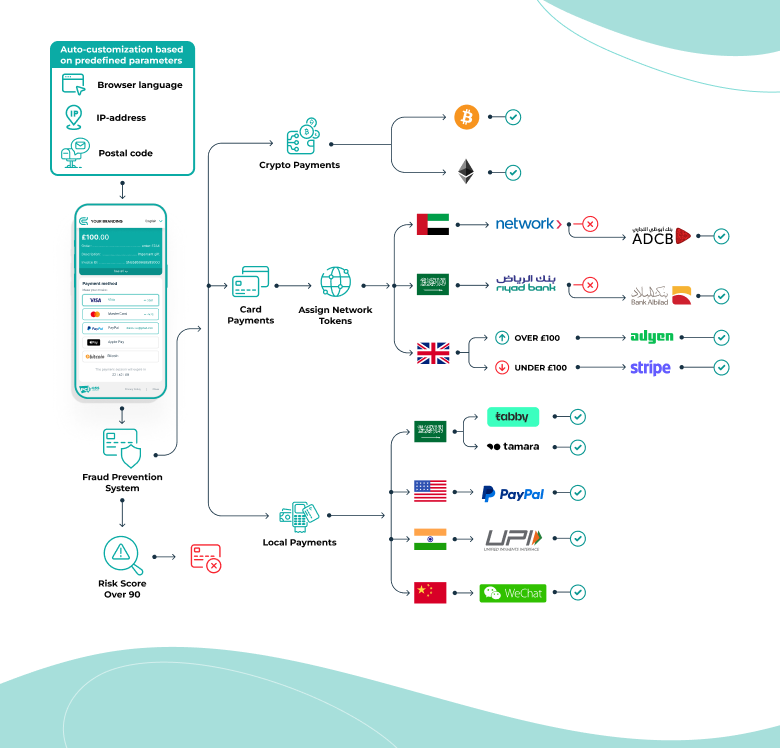
New payment methods, additional integrations, and regional differences introduced more routing paths and failure modes. In some cases, fallback behavior wasn’t explicit, leading to inconsistent outcomes during partial outages. In others, retries and failovers risked amplifying downstream instability rather than containing it.
The core problem was ensuring that routing decisions optimized for successful outcomes without introducing fragility or hidden coupling between systems.
My Role
I was responsible for how routing and reliability concerns were handled as first-class product problems rather than purely technical ones.
That meant working with engineering and operations teams to define clear routing intent, failure behavior, and recovery expectations before changes were made. I focused on making routing decisions explicit like which paths were preferred, when failover should occur, and what “graceful degradation” actually meant in practice.
A significant part of the role involved balancing competing priorities: maximizing transaction success, minimizing latency, and preventing retry storms or cascading failures during incidents. Decisions were made with an eye toward operational clarity, not just steady-state performance.
Decisions
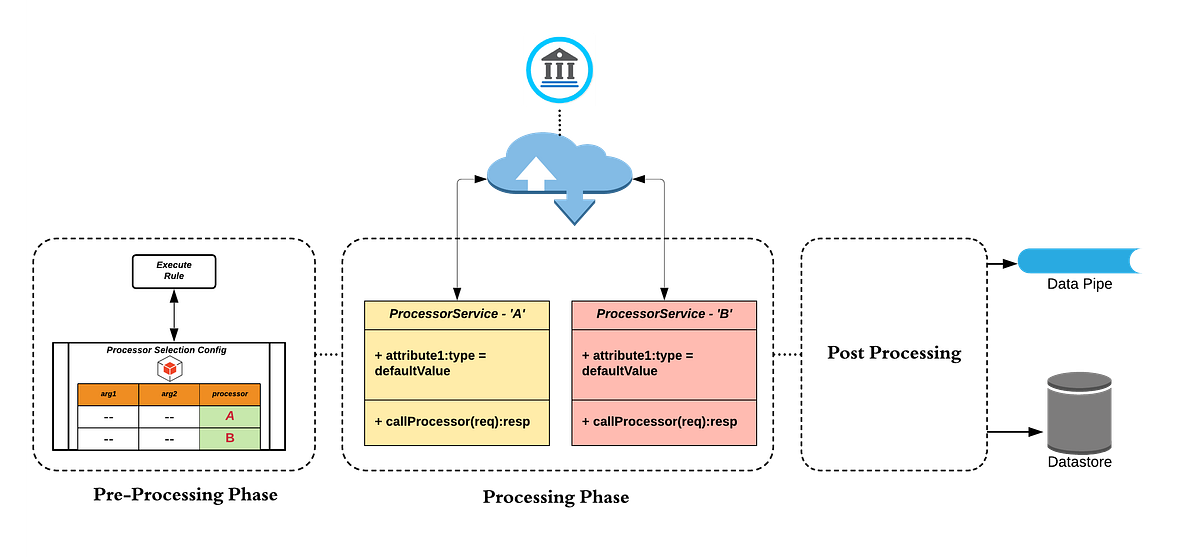
One important decision was to standardize routing behavior across transaction types rather than allowing ad hoc logic to emerge for each new integration. This reduced long-term complexity and made failure scenarios easier to reason about.
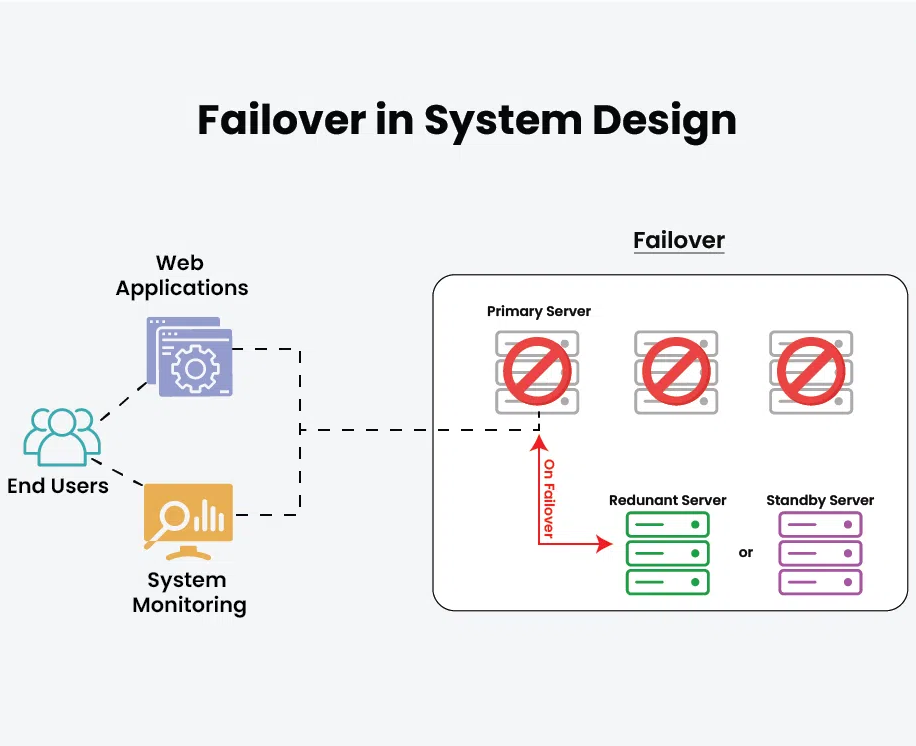
Another was being conservative with retries and failover. Rather than retrying aggressively in all cases, routing logic was designed to distinguish between transient failures and systemic issues, avoiding patterns that could overload downstream systems during outages.
There were also deliberate choices around observability. Routing decisions and fallback behavior needed to be visible and explainable so operations teams could quickly understand what the system was doing under stress.
Risks
Poor routing decisions could create subtle but serious issues:
-
Increased declines during partial outages
-
Cascading failures caused by uncontrolled retries
-
Longer incident resolution times due to unclear system behavior
Managing these risks required treating reliability as an outcome of product decisions, not just infrastructure tuning.
Outcomes
The routing layer became more predictable under load and more resilient during failures. Transaction success rates held steady during traffic spikes and partial outages, and incident response became faster because routing behavior was easier to understand and reason about.
Over time, the platform shifted from reactive incident handling to more intentional reliability design, with routing decisions aligned to business and customer impact.