Users
Home Buyers, Sellers, Real Estate Agents, Market Analysts
Industry
Real Estate / PropTech
Product Stage
Production-Grade AI System (Decision Support at Scale)
Property Price Prediction AI Models
Property pricing sits at the intersection of market psychology, financial constraints, and incomplete information. While historical sale prices are available, translating them into reliable, forward-looking price signals is far from trivial especially in markets where supply is thin, demand is volatile, and listing strategies vary widely.
This work focused on building AI-based property price prediction models that moved beyond static comparables and toward context-aware, probabilistic pricing insights that could support buyers, sellers, and agents in real decision-making moments.
Context and Scope
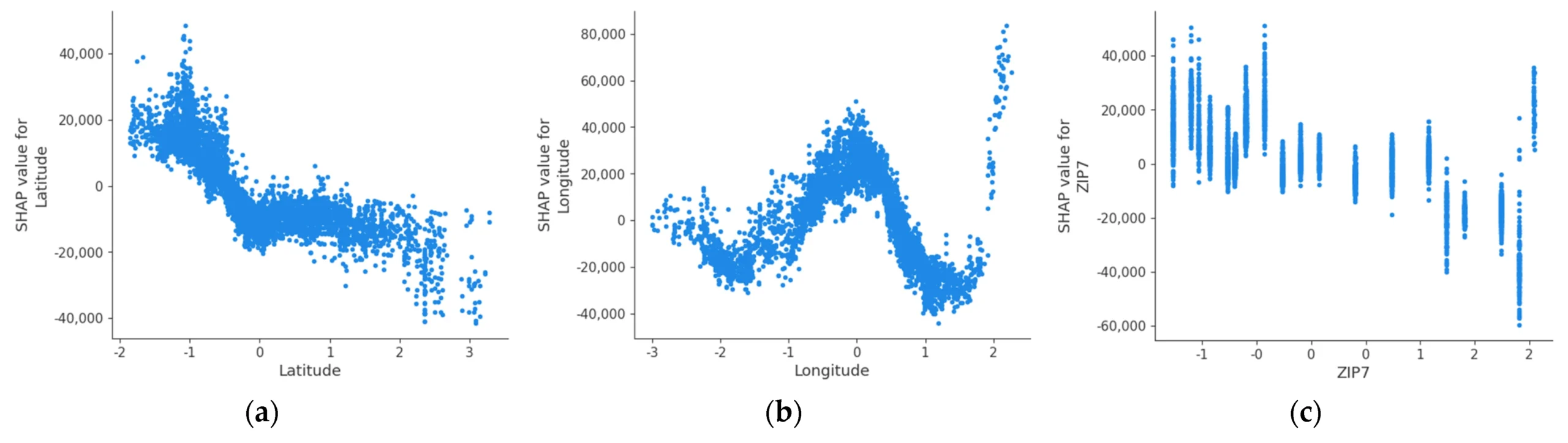
The platform operated in a residential real estate market where pricing decisions were influenced by far more than recent sales. Micro location effects, listing behavior, seasonality, interest rates, and buyer sentiment all played a role often interacting in non-linear ways.
Users approached pricing with different intents. Buyers wanted to know whether a listing was overpriced or likely to sell above asking. Sellers wanted guidance on where to price to balance speed and outcome. Agents needed defensible, data-backed narratives to support conversations with clients.
Existing tools relied heavily on lagging indicators and human intuition. The opportunity was to introduce predictive signal, not just descriptive history.
The Problem
Historical comparables alone were insufficient.
They failed in low-liquidity areas, struggled with rapidly changing market conditions, and often ignored listing strategy effects such as underpricing to drive bidding. Simple regression approaches produced point estimates that appeared precise but were misleading in practice.
The core problem was building models that could:
-
Adapt to changing market regimes
-
Handle sparse or noisy data
-
Express uncertainty explicitly
-
Be trusted by non-technical users making high-stakes decisions
Accuracy alone was not enough. Interpretability, stability, and usability were equally critical.
My Role
I owned the product and modeling strategy end to end.
That included defining prediction objectives, selecting modeling approaches, prioritizing input signals, and determining how outputs would be surfaced to users. I worked closely with data engineering and analytics workflows to ensure that training data reflected real market behavior rather than artifacts of listing or reporting bias.
A significant part of my responsibility was deciding what not to model, avoiding signals that introduced leakage, amplified bias, or reduced robustness across market conditions.
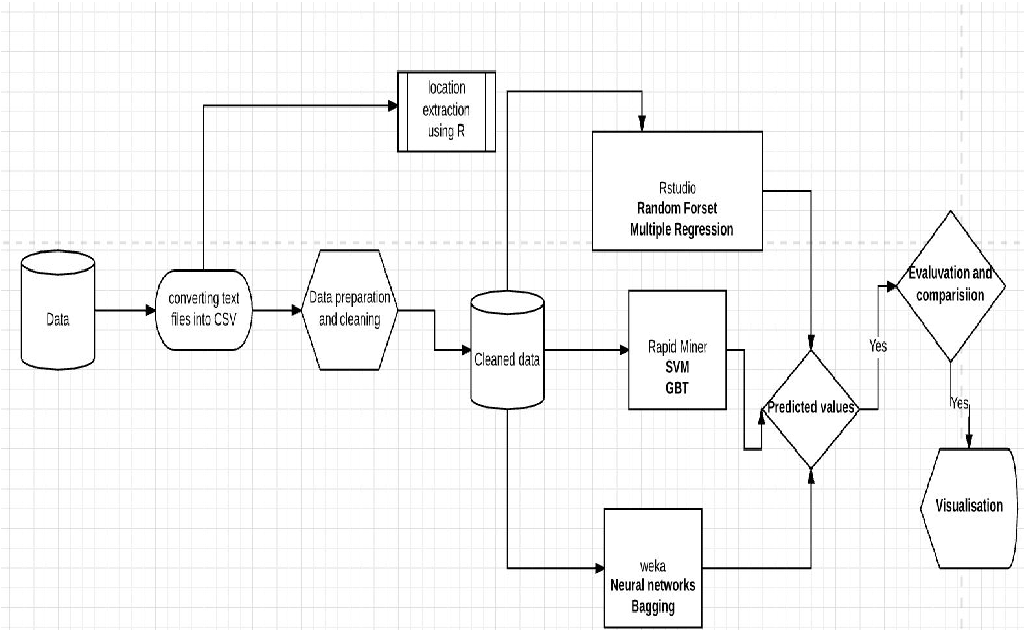
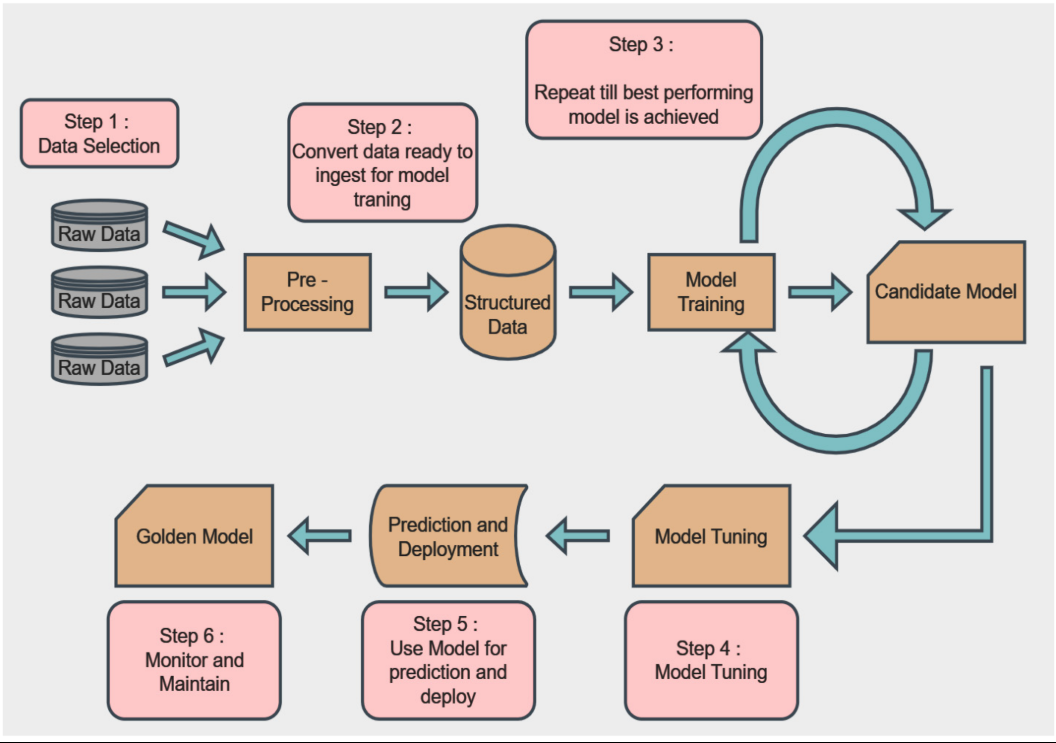
Modeling Approach & Product Decisions
Rather than treating price prediction as a single output, the system was designed around multiple complementary models.
Baseline models anchored predictions to recent comparable sales, adjusted for property characteristics and location features. On top of that, machine learning models incorporated behavioral and market dynamics such as listing velocity, days on market patterns, price change behavior, and local demand intensity.
Crucially, predictions were expressed as ranges and confidence bands, not single-point values. This aligned better with how real estate decisions are made and reduced false precision.
I also prioritized explainability. Model outputs were paired with contextual signals — for example, whether the model expected above-ask outcomes, pricing pressure, or softening demand so users could understand why a prediction looked the way it did.
Data & Signal Challenges
Real estate data is messy.
Listings are duplicated, modified, withdrawn, and relisted. Sale prices lag market behavior. Property attributes are inconsistently structured. Neighborhood boundaries are fuzzy rather than fixed.
Addressing this required careful feature engineering, normalization across data sources, and ongoing monitoring to detect drift. Models were evaluated not just on aggregate error metrics, but on directional correctness and stability across time windows.
I deliberately avoided overfitting to short-term anomalies, prioritizing signals that generalized across market cycles.
Risks
AI-based pricing carries real risk.
Overconfident predictions could mislead users. Bias in training data could disadvantage certain property types or neighborhoods. Model drift could silently degrade accuracy as market conditions shifted.
To manage these risks, predictions were framed as decision support, not guarantees. Confidence levels were surfaced, and guardrails were placed around when predictions would or would not be shown based on data sufficiency.
Trust was treated as a product constraint, not an output metric.
Go-To-Market
The go-to-market strategy focused on augmenting existing decision workflows, not replacing human judgment.
Price predictions were positioned as a second opinion, a way to sanity-check asking prices, anticipate competition, or understand market pressure rather than as authoritative valuations. This framing reduced resistance and increased adoption among users who were already skeptical of automated pricing tools.
Internally, predictions were integrated alongside other market insights, reinforcing that AI was one input into a broader decision context rather than a standalone feature.
Outcomes
The pricing models improved users’ ability to reason about value and market dynamics. Buyers gained clearer signals about over- and under pricing, sellers had better guidance on pricing strategies, and agents were able to anchor conversations in data rather than intuition alone.
From a platform perspective, predictive pricing increased engagement with property detail pages and drove deeper exploration of market insights, reinforcing the product’s value as a decision-support tool rather than a listing directory.