Designing a Resilient Payments Authorization Platform at Scale
What this platform is and why it matters
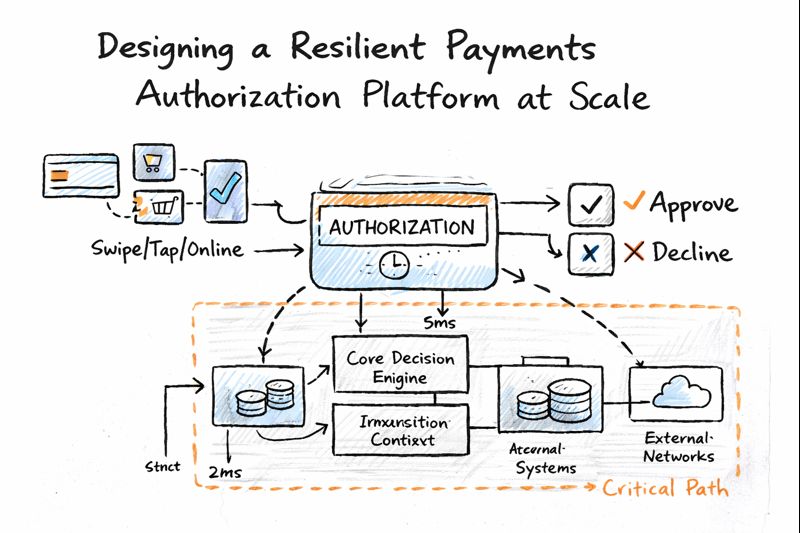
At the center of any card payment is an authorization decision that has to happen in real time. Every tap, swipe, or online checkout depends on this platform responding within milliseconds, with a decision that is accurate, consistent, and defensible. If it fails, the impact is immediate and visible like customers abandon transactions, merchants lose revenue, operations teams get flooded, and risk exposure increases.
What makes authorization especially challenging is that even small changes can have a large blast radius. A slight latency increase, an overly strict rule, or an unstable dependency can affect millions of transactions in a very short period of time. This platform wasn’t just a technical system; it was a core business capability that directly influenced customer experience, revenue, fraud losses, and regulatory posture.
Context
When I took ownership of the authorization platform, it was already operating at high scale, but the environment around it was changing quickly. Transaction volumes were increasing year over year, but more importantly, traffic patterns were becoming spikier due to digital wallets, e-commerce peaks, and new partner flows. At the same time, the decision logic inside the platform was expanding to support new payment methods, BNPL flows, and additional risk signals.
The system had multiple upstream and downstream dependencies, and while it was generally stable, it was increasingly sensitive to latency regressions and partial outages. Governance requirements also meant that changes couldn’t be rushed, every modification needed to be auditable, reversible, and compliant with internal risk and regulatory standards. The challenge was not simply to add features, but to evolve the platform in a way that made it safer, more resilient, and easier to scale over time.
The problem
The core problem was how to continue evolving a mission-critical authorization system without compromising reliability, latency, or regulatory controls. Adding more checks and integrations increased decision quality, but also increased the risk of slowdowns and failures. Improving approval rates could unlock revenue, but only if fraud exposure remained tightly controlled. Every decision involved trade-offs, and those trade-offs needed to be made deliberately at a platform level, not feature by feature.
My role
I owned the product strategy and roadmap for the authorization platform with a focus on resilience, scalability, and decision quality. My responsibility went beyond delivery. I worked closely with engineering, risk, compliance, operations, and partner teams to define what “safe evolution” looked like for a system with a very high blast radius.
This meant setting guardrails around what could be changed on the critical path, defining acceptable fallback behaviors, and ensuring we had the right instrumentation to understand the impact of changes quickly. I was accountable for prioritization, for aligning stakeholders with different incentives, and for making sure platform health was treated as a first-class product outcome rather than background infrastructure work.
The approach
The approach
1. Framing the problem as a constrained system
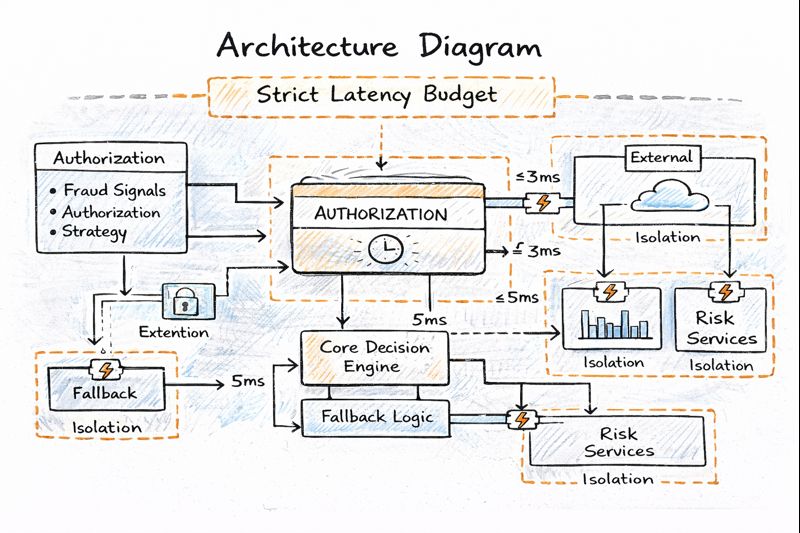
I treated the authorization flow as a system with explicit latency, reliability, and dependency budgets. Instead of evaluating changes in isolation, we looked at the entire end to end path and defined how much time and risk each component was allowed to consume. This created a shared language across product, engineering, and risk teams, and made trade-offs visible and intentional rather than implicit.
2. Designing for dependency failure, not just success
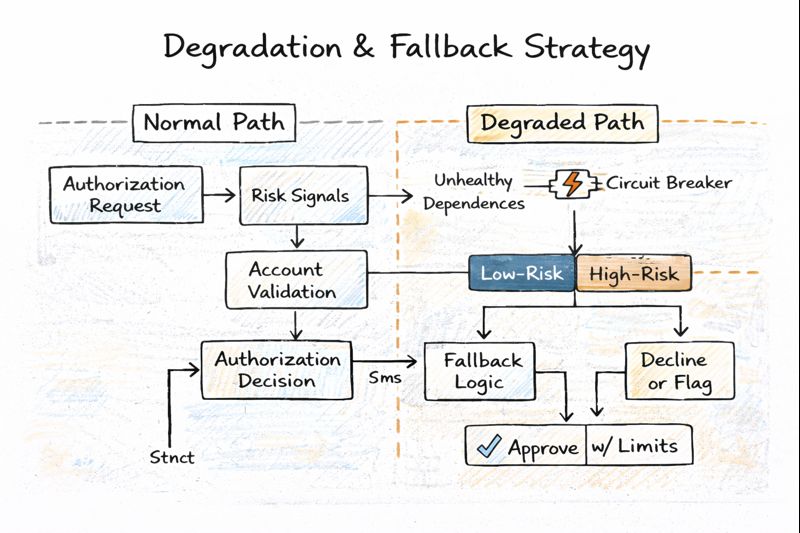
I prioritized reducing the platform’s sensitivity to downstream failures by standardizing timeout policies, introducing circuit breakers, and isolating critical components. Rather than relying on a single fail-open or fail-closed behavior, I worked with risk stakeholders to define tiered fallback strategies. Low-risk transactions could proceed with constrained approvals when certain signals were unavailable, while higher-risk flows degraded conservatively to protect loss exposure.
3. Making rollout safety a core product capability
Given the blast radius of authorization changes, I ensured all decision logic was shipped behind feature flags and policy controls. Rollouts were progressive and segmented by factors such as channel, region, or partner, allowing real-world behavior to be observed early. Clear rollback thresholds were defined upfront so changes could be reversed quickly if latency, error rates, or approval patterns deviated from expectations.
4. Building observability around decisions, not just systems
I pushed for observability that explained why decisions were happening, not just whether the system was up. Dashboards were designed to correlate approval rates, latency, retries, and error patterns across segments. This enabled faster incident diagnosis, clearer post-release evaluation, and more confident iteration on decision logic over time.
Trade-offs
One of the most consistent tensions was between improving approval rates and managing fraud exposure. There was always pressure to reduce declines, but doing so without careful segmentation risked introducing losses that would only surface weeks later. We chose a measured approach targeting specific segments where declines were demonstrably unnecessary, and expanding cautiously based on observed outcomes.
Another trade-off was between feature velocity and platform stability. New payment methods and partner integrations were valuable, but they increased complexity on the critical path. I deliberately carved out roadmap capacity for resilience and reliability work, framing it as an enabler of future growth rather than a cost center.
There were also moments where local optimizations conflicted with global consistency. Some markets or partners wanted bespoke behaviors, but we resisted fragmentation by designing policy-driven configuration rather than hard forks in logic. This kept the platform maintainable while still allowing controlled variation where it mattered.
Operating model
The roadmap for the authorization platform was organized around quarterly themes rather than isolated features. Each theme balanced business goals, platform health, and risk considerations. Changes affecting the critical path went through structured design reviews that included product, engineering, and risk stakeholders, with explicit discussion of latency impact, fallback behavior, and rollback plans.
Release cadence was frequent but controlled. Smaller changes were preferred over large bundled releases, and each change had predefined success and failure signals. This operating model reduced debate during incidents because expectations and decision criteria were agreed upon in advance.
Architecture narrative
At a high level, the authorization flow was designed around a core decision engine with clearly bounded dependencies. The transaction entered the system, basic validations were performed, and the request flowed through policy-driven decision logic. External risk and account services were treated as optional enhancers rather than mandatory blockers.
Isolation mechanisms ensured that if a downstream service exceeded its time budget or returned errors, the system could fall back to predefined decision paths. Circuit breakers prevented repeated calls to unhealthy dependencies, and feature flags allowed rapid disabling of newly introduced logic. This architecture made it possible to keep decisions flowing safely even when parts of the ecosystem were under stress.
Outcomes
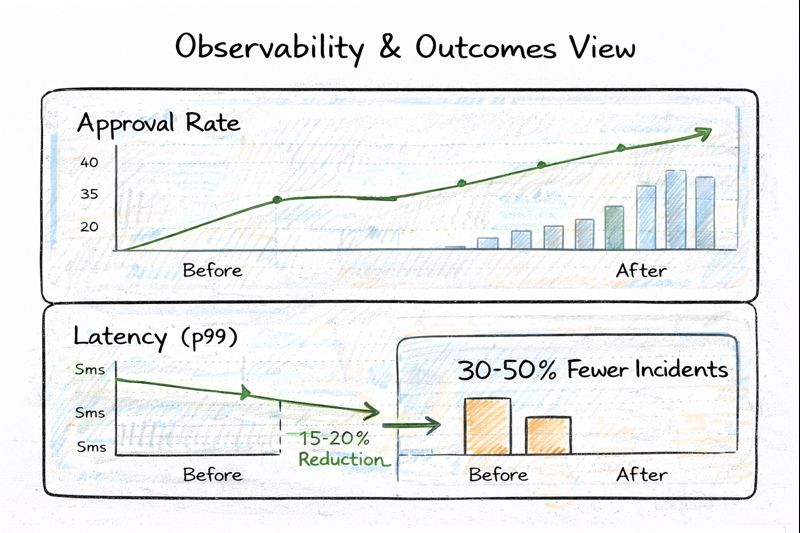
Over time, these changes materially improved the platform’s ability to handle growth without increased operational risk. Reliability incidents tied to dependency degradation were reduced, and when issues did occur, they were detected and mitigated faster due to better observability and clearer rollback mechanisms.
Latency became more predictable during peak periods, with p99 response times remaining within target thresholds even under bursty traffic conditions. Targeted authorization changes led to measurable approval-rate improvements in specific e-commerce and wallet segments, while fraud and chargeback metrics remained within acceptable bounds.
Equally important, the platform became easier to evolve. Engineering teams could ship changes with more confidence, risk teams had clearer visibility into decision behavior, and operations teams saw fewer customer-impacting escalations tied to authorization instability.